I was experimenting with some speech-to-text work using OpenAI’s Whisper models
today, and transcribing a 15-minute audio file with Whisper tiny model on AWS Lambda (3 vcpu) took 120 seconds. I was curious how faster this could be if I ran the same transcription model on a GPU instance, and with a quick search, modal.com
seemed like a nice option to spin up a GPU machine, run the code, and shut down the machine, similar to how AWS Lambda works.
The cheapest GPU instance on modal.com is Nvidia T4 which costs $0.000164 per second and uses AWS infrastructure behind the scenes. The free starter plan on modal.com includes $30 credit, enough to experiment and try their services. Although the documentation is good enough, it took me some time to figure out how to quickly run my code on a T4 GPU without worrying about docker images, so here is a quick guide on how to run your Python code on GPU instances on modal.com from scratch.
Preparation
After creating an account on modal.com , install their Python library:
pip install modal
and run the setup command:
modal setup
## or: python3 -m modal setup
This will open a web browser and if you’re logged in to your modal account, it will automatically generate a token and save it on your device.
Our code
You’ll first need to define the environment in which your code will be running. Start my_code.py with:
import modal
image = modal.Image.debian_slim()
app = modal.App(image=image)
Then include what you want to run remotely (on a GPU instance in this case) and wrap it with @app.function decorator:
@app.function(gpu="t4")
def square(x):
print("This code is running on a remote worker!")
return x**2
And finally, define an entry point function to call from your local machine when triggering the remote instance:
@app.local_entrypoint()
def main():
print("the square is", square.remote(42))
So the final state of my_code.py should be:
import modal
image = modal.Image.debian_slim()
app = modal.App(image=image)
@app.function(gpu="t4")
def run_remote(x):
print("This code is running on a remote worker!")
return x**2
@app.local_entrypoint()
def main():
print("the square is", run_remote.remote(42))
Note that t4 is the cheapest GPU available, and you can use other GPU instances
if you’d like. To run this dummy run_remote function on a GPU instance, trigger it with the following command on your local terminal:
modal run my_code.py
## or python3 -m modal run my_code.py
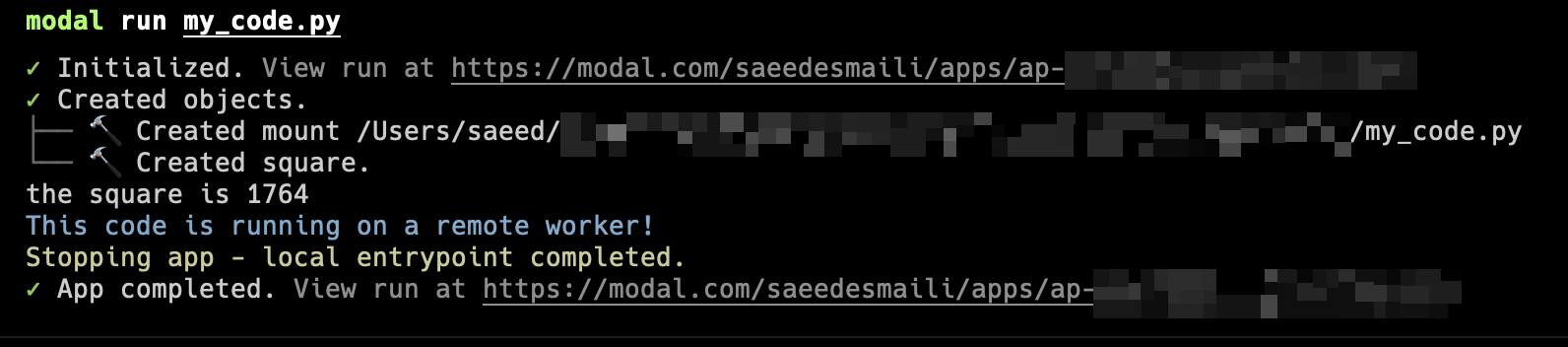
Nice! We were able to run a simple function on GPU. You can view the logs by clicking on the URL in the terminal (https://modal.com/<your-username>/apps/ap-<blah-blah-blah>) and monitor your credit usage on your billing page
.
More serious code
The above sample code can easily be found on the modal’s documentation, but stuff gets more complicated if you want to do more serious work. Getting back to my text-to-speech code, I had to add a few steps:
- Include a local audio file (what I want to transcribe) from my device.
- Install Python libraries (
openai-whisperandfaster-whisper). - Install
ffmpeg(it’s required foropenai-whisperto work).
Let’s start by refining our image and environment:
image = (
modal.Image.debian_slim()
.apt_install("ffmpeg")
.pip_install("openai-whisper", "faster-whisper")
.copy_local_file(
local_path="/<path-to-our-local-file>/<filename>.m4a",
remote_path="./tmp/",
)
)
app = modal.App(image=image)
And update our run_remote function with what we’ll need for transcribing an audio file:
@app.function(gpu="t4")
def run_remote():
print("This code is running on a remote worker!")
import time
import whisper
from faster_whisper import WhisperModel
file_path = "/tmp/<filename>.m4a"
whisper_model = whisper.load_model("tiny.en")
t1 = time.perf_counter()
result = whisper_model.transcribe(file_path)
print("time passed with openai-whisper: ", time.perf_counter() - t1)
model = WhisperModel("tiny.en", device="cuda", compute_type="float16")
t1 = time.perf_counter()
segments, info = model.transcribe(file_path, beam_size=5)
## note: `segments` is a generator, so we'll need to iterate over it to
## be able to get the transcription.
segments_result = list(segments)
print("time passed with faster-whisper: ", time.perf_counter() - t1)
return
@app.local_entrypoint()
def main():
run_remote.remote()
Note that we need to include the imports inside our run_remote function, as that’s what actually will be getting executed on the remote instance.
This is all we need, and by running the modal run my_code.py command and waiting for our audio to get transcribed (twice in this case), we should get the following result (of course, the actual values of time passed will be different depending on what GPU instance you use and the length of the file):
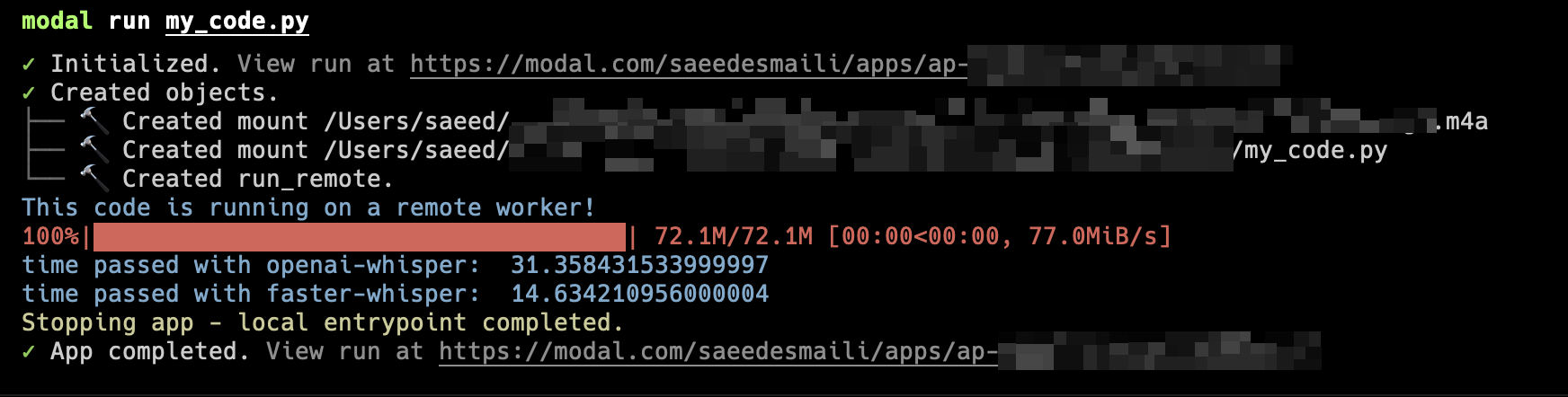
We can see that by running this transcription process on GPU, we reduced the time it takes to do the job from 120 seconds to 31 and 14 seconds. A very nice achievement, but we should take the important factor of pricing into account as well (maybe in a future post).
Troubleshooting
If you’re getting the following error when running faster-whisper (or any other code) with cuda:
Could not load library libcudnn_ops_infer.so.8. Error: libcudnn_ops_infer.so.8: cannot open shared object file: No such file or directory
you can fix it by explicitly setting the path of the cuda installations in your image definition using env (took me some time to figure out this fix):
image = (
modal.Image.debian_slim(python_version="3.11")
.env(
{
"LD_LIBRARY_PATH": "/usr/local/lib/python3.11/site-packages/nvidia/cublas/lib:/usr/local/lib/python3.11/site-packages/nvidia/cudnn/lib"
}
)
.apt_install("ffmpeg")
.pip_install("openai-whisper", "faster-whisper")
.copy_local_file(
local_path="/<path-to-our-local-file>/<filename>.m4a",
remote_path="./tmp/",
)
)
app = modal.App(image=image)
Using Jupyter notebook
If you’d like to have a quick exploration using a jupyter notebook, you can run the following command to spin up a GPU instance and experiment with your code:
modal launch jupyter --gpu t4
Note that you’ll be using your credit for the whole amount of time that this jupyter instance is up, even if you don’t run any code. Make sure to stop it by terminating the command on your terminal.