In my previous blog post
I explored using the unstructured python library for loading and parsing documents. As I mentioned in the post, although unstructured seems a very useful library, it has a few issues. Since I’m planning to do a semantic search on the paragraphs and feed the relevant ones to a large language model, the library’s inability to reliably identify headings and paragraphs was a big problem for me.
I then found a way to use pandoc with python, and this led me to spend a few hours trying it out to see if it improve my document parsing process and provide me more reliable results. And it did! In this post, I’ll walk you through how I used pandoc to load docx and md documents, create a table of content for each document, split the documents to paragraphs, and include the parent heading of each paragraph in the chunks, all using python.
Getting started
First of all, you need to make sure you have pandoc installed
on your machine. I will bring pandoc to python using sh
, but this can be achieved with pypandoc
as well. To follow along with me, you can download these three sample docx files: 1
, 2
, 3
, and put them in the /corpus directory.
To read a document and get a plain text output we can use this simple line of code:
from sh import pandoc
path = "corpus/sample-doc-without-title.docx"
doc = str(pandoc(path, "-t", "plain", "--toc", "--standalone"))
print(doc)

path is the document we want to load and parse (it can be a docx, md, or so many other formats that pandoc supports). Using -t and plain we ask pandoc to convert the document to a plaintext format, and --toc and --standalone flags are needed to generate the nice table of content at the beginning of the output.
This is already a very nice and usable output, but I want to split the text into paragraphs and prepend the parent heading to each paragraph as Heading [SEP] paragraph text, so the important content of headings isn’t lost when I use semantic search.
Parsing the headings
I experimented with various docx and md files to find out the different types of TOC and text I could possibly get, and the main three types are:
plaintext output when printed:

raw plaintext:
Sample doc with title\n\n\n- Introduction\n - A child heading of introduction\n- Summary\n\nIntroduction\n\nLorem Ipsum is simply dummy text of the printing and typesetting\nindustry. Lorem Ipsum has been the industry’s standard dummy text ever\nsince the 1500s, when an unknown printer took a galley of type and\nscrambled it to make a type specimen book. It has survived not only five\ncenturies, but also the leap into electronic typesetting, remaining\nessentially unchanged. It was popularised in the 1960s with the release\nof Letraset sheets containing Lorem Ipsum passages, and more recently\nwith desktop publishing software like Aldus PageMaker including versions\nof Lorem Ipsum.\n
plaintext output when printed:

raw plaintext:
- Introduction\n - A child heading of introduction\n- Summary\n\nIntroduction\n\nLorem Ipsum is simply dummy text of the printing and typesetting\nindustry. Lorem Ipsum has been the industry’s standard dummy text ever\nsince the 1500s, when an unknown printer took a galley of type and\nscrambled it to make a type specimen book. It has survived not only five\ncenturies, but also the leap into electronic typesetting, remaining\nessentially unchanged. It was popularised in the 1960s with the release\nof Letraset sheets containing Lorem Ipsum passages, and more recently\nwith desktop publishing software like Aldus PageMaker including versions\nof Lorem Ipsum.\n
plaintext output when printed:

raw plaintext:
Lorem Ipsum is simply dummy text of the printing and typesetting\nindustry. Lorem Ipsum has been the industry’s standard dummy text ever\nsince the 1500s, when an unknown printer took a galley of type and\nscrambled it to make a type specimen book. It has survived not only five\ncenturies, but also the leap into electronic typesetting, remaining\nessentially unchanged. It was popularised in the 1960s with the release\n
This python function will identify the type of a document:
import re
def identify_doc_type(doc):
'''
categorizes a plaintext doc based on the format of the toc.
'''
if re.search(r'.*\n\n\n-\s{3}.*', doc):
return "TOC_WITH_TITLE"
elif re.search(r'-\s{3}.*\n\n.*', doc):
return "TOC_WITHOUT_TITLE"
else:
return "NO_TOC_TITLE"
And it can be used for splitting the table of content from the text when reading the doc:
def read_doc(path):
'''
reads a text file and returns toc and full text.
'''
doc = str(pandoc(path, "-t", "plain", "--toc", "--standalone"))
doc_type = identify_doc_type(doc)
if doc_type == "TOC_WITH_TITLE":
doc = re.sub('.*\n\n\n-', '-', doc)
toc, text = doc.split('\n\n', 1)
elif doc_type == "TOC_WITHOUT_TITLE":
toc, text = doc.split('\n\n', 1)
else:
toc, text = "", doc
return toc, text
And it’s always nice to clean up the paragraphs to remove unnecessary new line characters, images, etc:
def cleanup_plaintext(text):
'''
gets the full text of a document and returns cleaned-up text.
'''
# Remove images
text = text.replace("[image]", "")
text = text.replace("[]", "")
# Replace single \n with space (if the next char is not \n or -)
text = re.sub('(?<!\n)\n(?!(\n|-))', ' ', text)
# Replace any sequence of two or more newlines with \n\n
text = re.sub('\n{2,}', '\n\n', text)
# Replace multiple spaces with single space
text = re.sub('(?<!\n) +', ' ', text)
return text
Now that we know what are the headings of our document, we can split the text into paragraphs while prepending the parent headings:
def split_text(toc, text):
'''
gets the toc and cleaned text, and returns chunks of texts:
["Heading [SEP] Text", ]
'''
headings = [line.strip('- \n') for line in toc.split('\n')]
paragraphs = text.split("\n\n")
current_heading = ""
list_group = ""
text_chunks = []
for para in paragraphs:
# use the new heading if we've moved to a new heading section
if len(headings) > 0 and para == headings[0]:
current_heading = headings[0]
headings.pop(0)
continue
# group bullet points as a single chunk of text
if para.startswith("- "):
list_group += para + " "
continue
elif list_group != "":
para = list_group
list_group = ""
# if we're at the beginning of a document and
# we haven't seen any headings yet
if current_heading == "":
text_chunks.append(para.strip())
else:
text_chunks.append(f"{current_heading} [SEP] {para}".strip())
return text_chunks
Note that this will group bullet point lists in a single paragraph, as their content most probably is related to each other.
Let’s finalize this process and get the text chunks for all the documents in a directory and store them in a pandas dataframe:
import os
import pandas as pd
df = pd.DataFrame()
root_dir = 'corpus'
allowed_filetypes = ['.md', '.docx', '.pdf']
for directory, subdirectories, files in os.walk(root_dir):
for file in files:
filename, filetype = os.path.splitext(file)
if filetype in allowed_filetypes:
full_path = os.path.join(directory, file)
toc, text = read_doc(full_path)
text_cleaned = cleanup_plaintext(text)
text_chunks = split_text(toc, text_cleaned)
df_new = pd.DataFrame(text_chunks, columns=["text"])
df_new[["directory", "filename", "filetype"]] = directory, filename, filetype
df = pd.concat([df, df_new])
df.reset_index(drop=True, inplace=True)
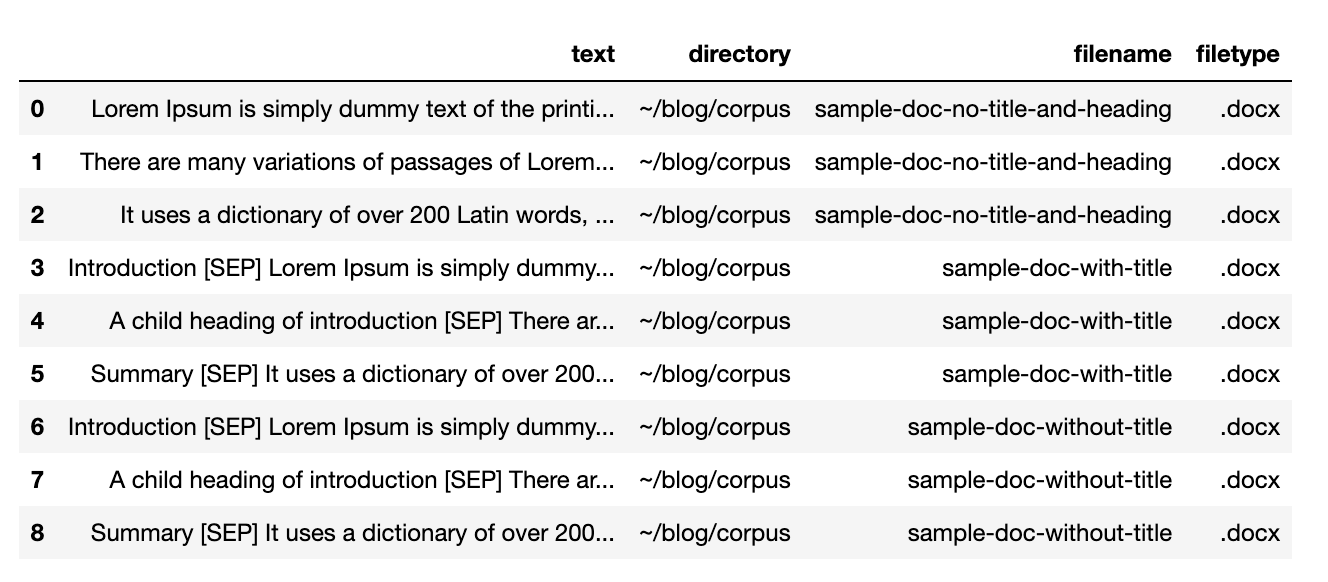
The result is a nice dataframe with texts ready to be converted to vectors using an embedding model :
Are we done?
Our cleaning and splitting process still can be improved, as there are a few issues with the current approach:
- We should parse or remove footnotes and their references in the plaintext output. They appear in the text as
[N]and at the end of the text as[N] some footnote text). - We can preserve even more heading information in the final text chunks by including all the parent headings (e.g.
Heading 1 [SEP] Heading 2 [SEP] Paragraph text). - We can include filenames in the final text chunks, as they also contain useful information.
- The code blocks (in
mdfiles for example) are grouped as normal text paragraphs. This is a good enough approach for my documents, but it’s not ideal. - If our documents include tables, our cleanup process considers them as normal text paragraphs. So tables end up as chunks with so many dashed lines and a more robust parsing approach is needed to preserve their information.
- We’re not considering the length of each chunk when splitting the text. Given that each embedding model has a specific max token size, we should add another step to split the chunks if they are larger than a specific size.
Please reach out if you have suggestions for any of these problems or any improvement ideas for my parsing functions.